围绕 Agent 的讨论很容易停在“提示词怎么写”这一层,但系统一旦进入真实业务,重心很快会转到另一组问题:任务怎么拆、工具怎么接、执行过程怎么回看、长链路任务怎么中途修正。
这篇文章的价值正在这里。它没有把 Agent 当成一个会说话的模型,而是把它看成一个带有编排能力的工作流系统。从这个角度看,Prompt 只是接口,真正决定效果的是工作流结构。
文中把常见模式分成两大类:
Reflection-focused:强调复盘、校正、反馈回路。Planning-focused:强调先规划、后执行、按依赖推进。
这个划分很实用,因为它对应了 Agent 最常见的两类失效:
- 没有反思能力,做错一步后一路错下去。
- 没有规划能力,拿到复杂任务就直接开跑,结果上下文越来越乱。
从工程实现看,还可以再补一层理解:这些模式本质上都在调整四个旋钮。
- 推理与行动是否交替进行。
- 任务是否先被拆成计划。
- 结果是否要经过反馈回路再修正。
- 多个执行步骤是串行还是并行。
理解这四个旋钮,比死记模式名字更重要。很多团队最后并不是“选择某个标准模式”,而是在这些模式之间做裁剪和拼装。
一、工作流不是 Prompt 模板,而是任务编排器
原文有一个很明确的判断:工作流应该被视为一个 orchestrator。在这个编排器里,每个节点都可以代表不同类型的执行单元:
- 一次 LLM 推理
- 一次函数调用
- 一次检索任务
- 一次 RAG 步骤
也就是说,Agent 不是“一个大模型加几个工具”这么简单,而是“一个状态机驱动的执行图”。图里的边决定依赖关系,节点决定调用什么能力,循环则决定什么时候复盘、什么时候继续推进。
这也是为什么真正可用的 Agent 体系,最终都会落回到工作流设计。
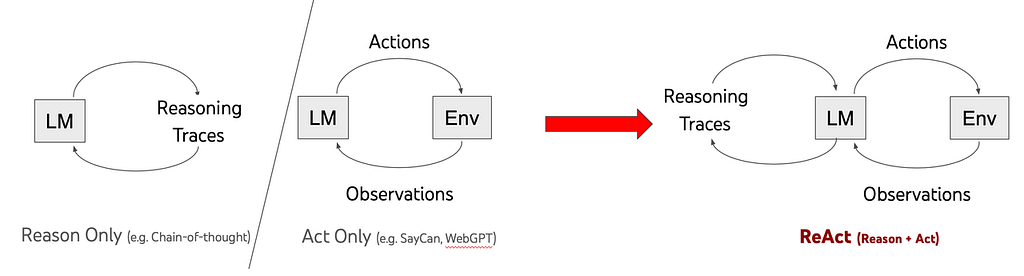
二、ReAct:把推理和动作接成闭环
ReAct 是最经典的 Agent 工作流之一。它解决的是一个很具体的问题:模型不能只会想,还得边做边看结果,再决定下一步。
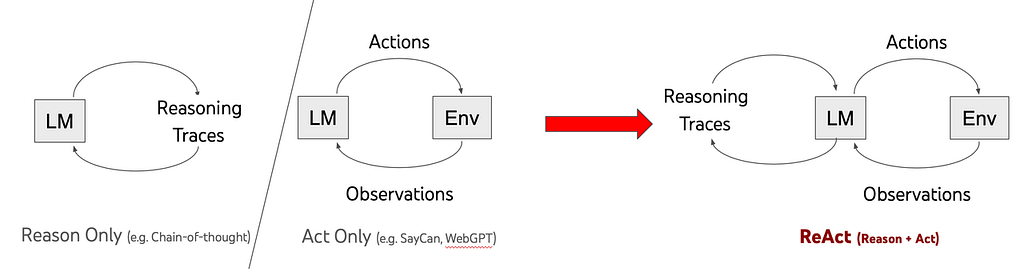
在 ReAct 之前,推理和行动经常是分离的。模型先产出一串完整推理,再照着执行。但真实任务不是这样。只要环境里有反馈,执行就应该反过来影响后续推理。
原文举的例子很形象:找桌上的笔。
如果没有 ReAct,流程可能是把“笔筒、抽屉、显示器后面”全查一遍。
而有了 ReAct,流程会变成:
- 先查笔筒。
- 没有,继续查抽屉。
- 在抽屉里找到,动作结束。
这就是 ReAct 的本质:每执行一步,都把环境反馈重新喂回推理环路。
ReAct 在代码里通常怎么落地
原文把实现拆得很清楚,基本上就是一个持续迭代的提示词循环:
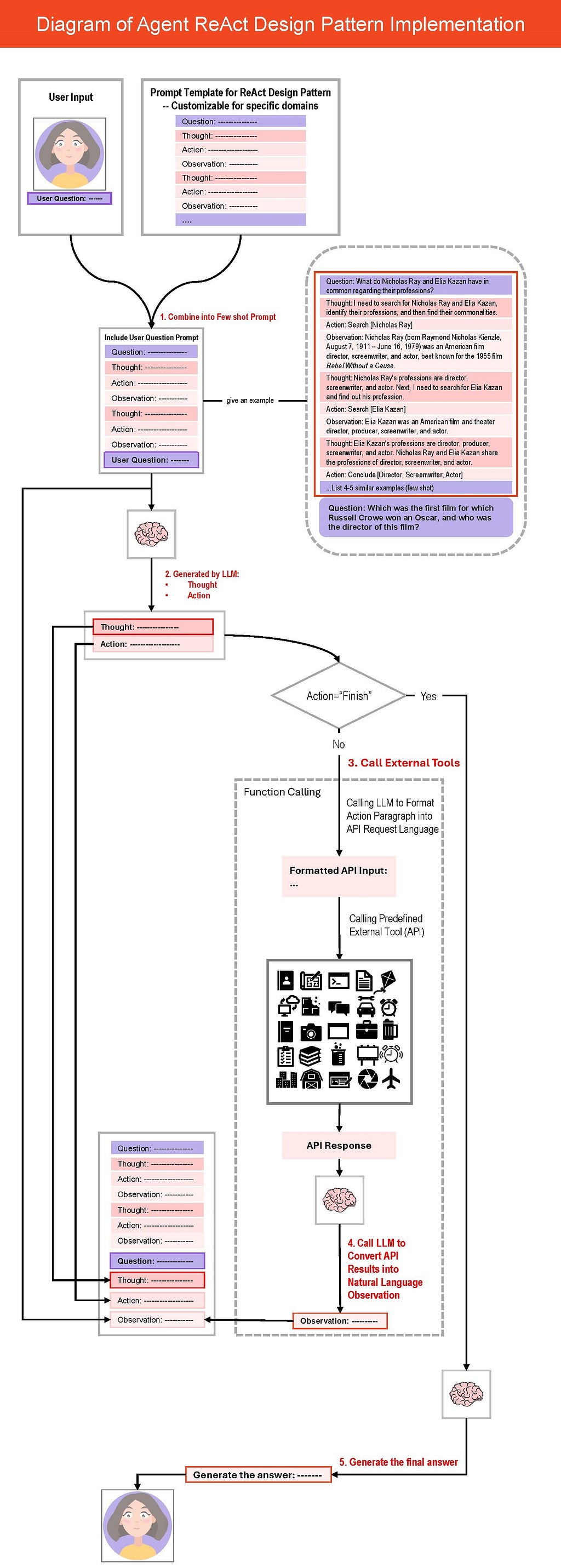
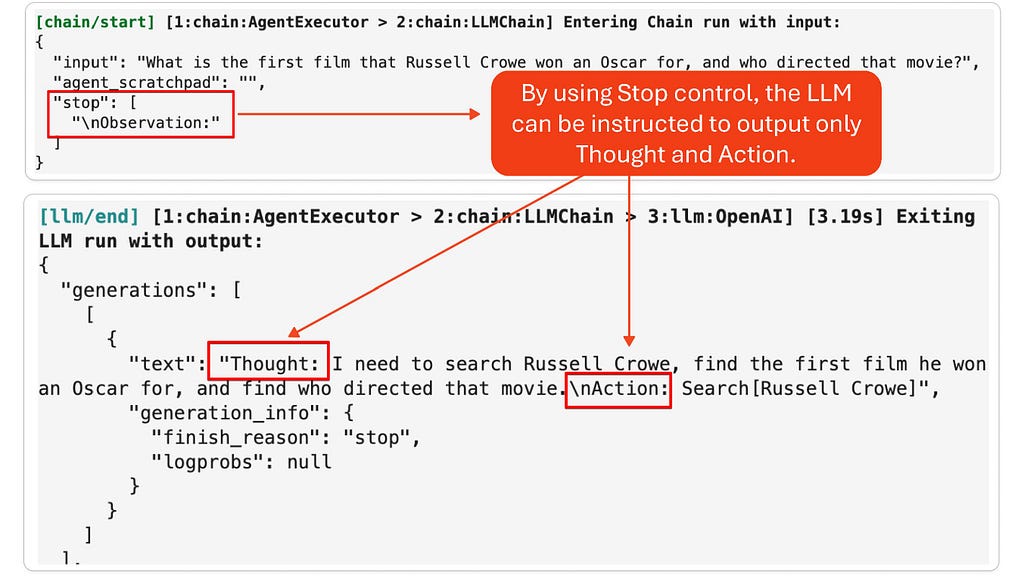
- 先把用户问题塞进固定模板,模板里显式约束
Question -> Thought -> Action -> Observation。 - 让模型先生成
Thought + Action,但通过停止词控制,不让它把Observation也脑补出来。 - 把
Action映射到具体工具调用。 - 把工具返回值转成
Observation,再喂回下一轮推理。 - 一直循环到模型产出
Finish或等价结束动作。

这个模式落地时有两个真正关键的地方:
- few-shot 模板要把思考路径约束清楚。
- 工具定义要稳定,动作输出必须能可靠映射成函数调用。
很多所谓 Agent“不稳定”,最后查下来都不是模型不会推理,而是这两个接口层没设计好。
ReAct 适合什么场景
ReAct 最适合这类任务:
- 步骤不算特别长,但每一步都依赖外部反馈。
- 工具调用是串行推进的。
- 当前环境状态会快速改变下一步决策。
典型例子包括:
- 网页浏览
- 简单客服查单
- 运维排障
- 数据查询后继续追问
如果任务已经长到需要显式拆计划,单纯 ReAct 往往不够。它擅长局部闭环,不擅长长程编排。
三、Plan & Solve:先拆任务,再逐步执行
Plan & Solve 解决的是另一类问题:任务太长,不能想到什么做什么,必须先形成一个中间计划。
如果说 ReAct 更像“边走边看”,那 Plan & Solve 更像“先列施工单,再开始施工”。
原文用做咖啡举例很贴切。做 flat white 这种事,通常不是一步一步盲走,而是先有大致流程;如果中途发现没牛奶,计划还要能被重写。
从实现上看,这个模式至少包含两个角色:
Planner:先生成多步计划。Executor:按步骤执行。
更完整的版本还会加一个:
Replanner:在某一步完成后,根据当前状态修订后续步骤。
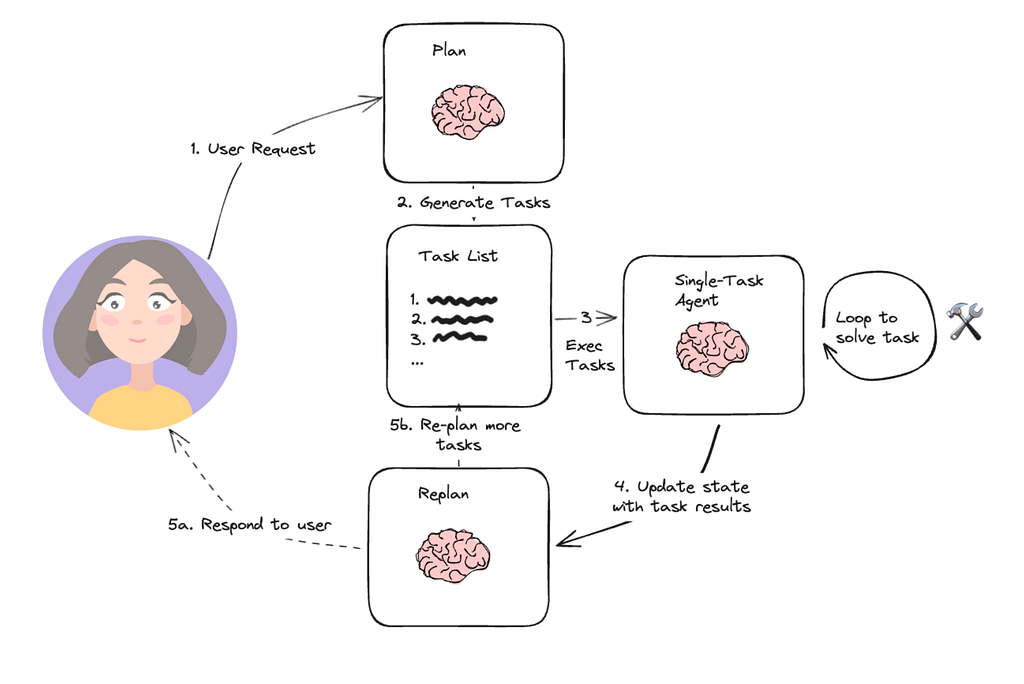
这个结构的意义不只是“把任务拆小”,而是把任务分解能力从执行能力里单独拿出来。拆解、修订、执行,各自承担不同职责,系统可控性会明显更强。
Plan & Solve 的优点和代价
优点很明显:
- 更适合长链路任务。
- 对复杂依赖更友好。
- 更容易在中途插入检查点。
代价也同样明显:
- 计划本身可能是错的。
- 重规划会消耗更多 token。
- 如果执行器能力弱,再好的计划也落不了地。
所以它适合复杂任务,但不适合所有任务。简单任务硬上 Planner,通常只是多一层开销。
四、其他模式可以按“补强什么能力”来理解
原文后半部分列了几个常见模式。与其把它们背成名词表,不如直接看它们分别在补哪块短板。
1. REWOO:减少显式 Observation 的循环成本
REWOO 可以理解成对 ReAct 的一次裁剪。它不再强制每一步都显式写出 Observation,而是把观察结果隐式并入下一执行单元。
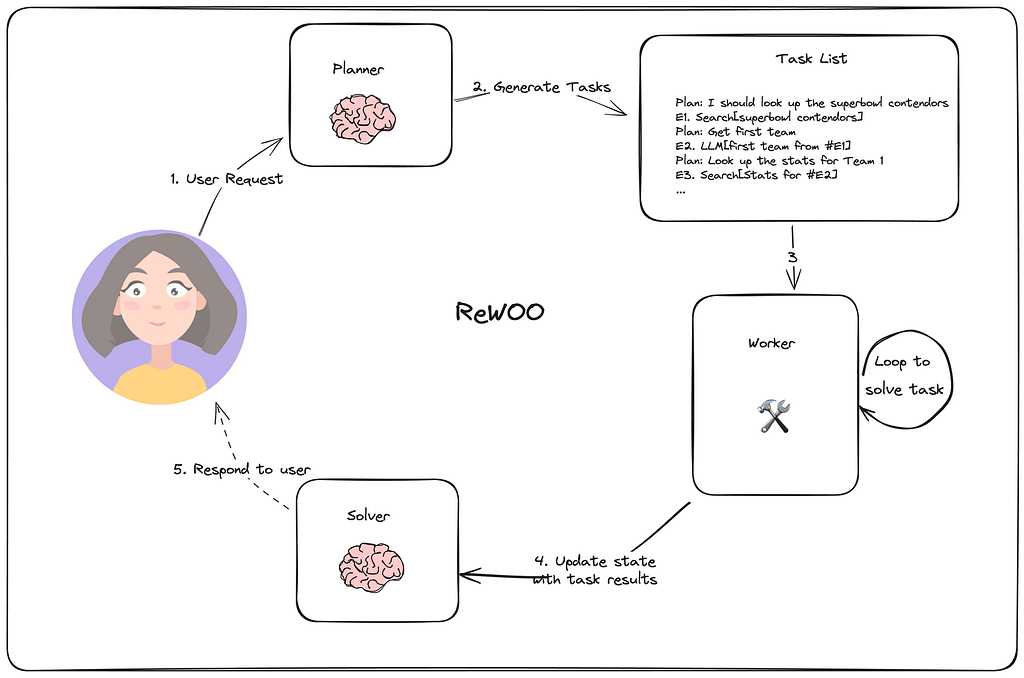
这种写法的好处是流程更轻,尤其适合那些工具输出结构比较稳定、没必要每轮都重新组织自然语言反馈的任务。
从工程角度看,REWOO 不是“更高级的 ReAct”,而是更省上下文、更省回路成本的 ReAct 变体。
2. LLMCompiler:把可并行的工具调用并行掉
LLMCompiler 的核心思路很直接:如果几个步骤彼此独立,就不要硬串行。
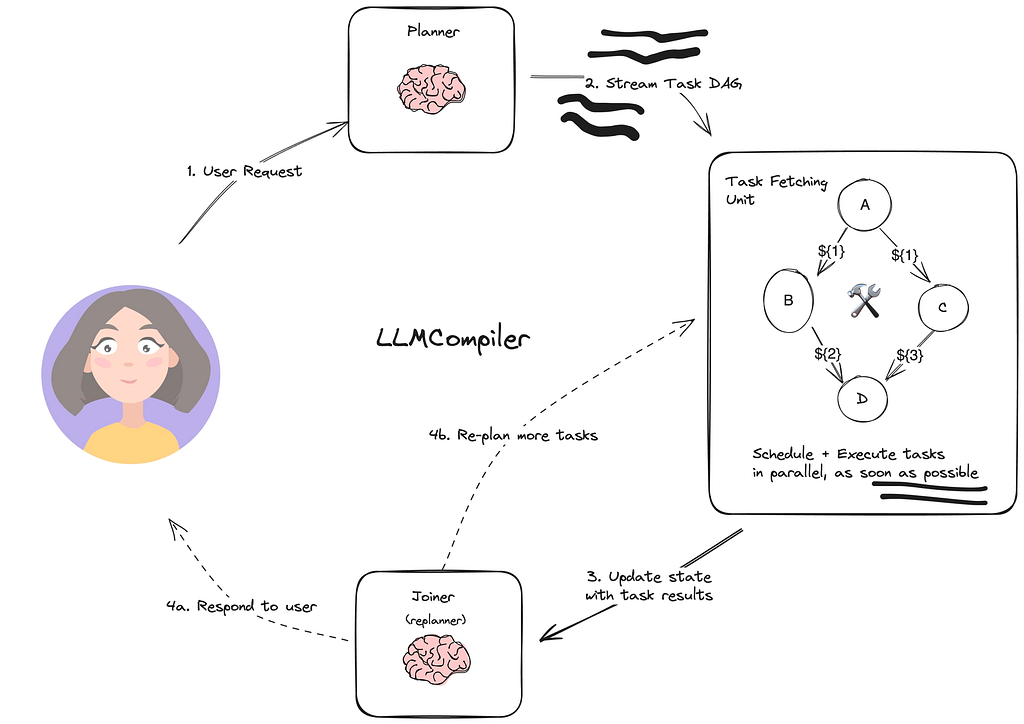
这类模式特别适合:
- 多来源检索
- 多字段信息汇总
- 多个独立子问题并发求解
它真正提升的不是“模型更聪明”,而是系统执行效率。
如果任务之间有依赖关系,强行并行反而会把错误放大。
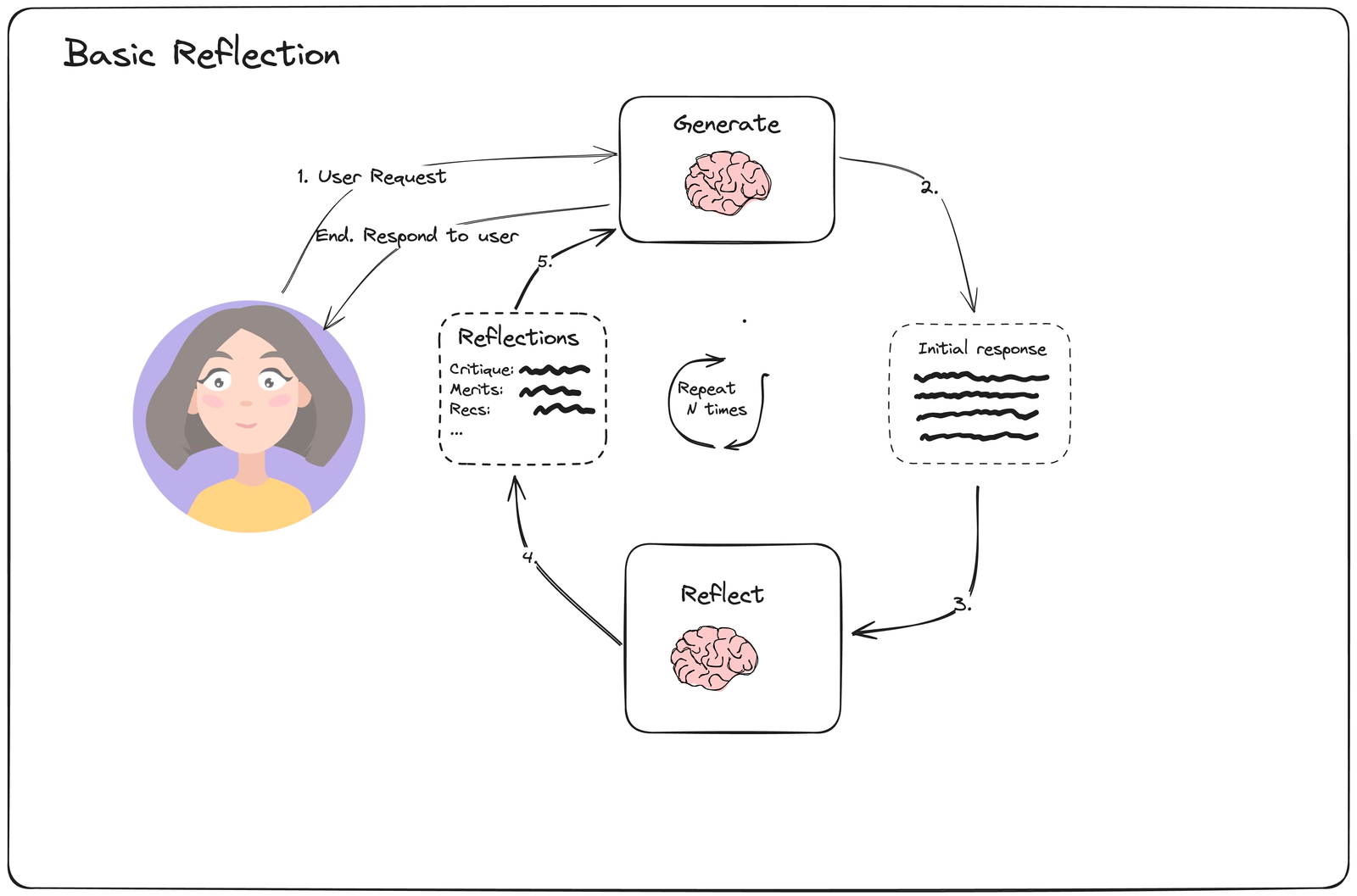
3. Basic Reflection:先产出,再批改,再回炉
Basic Reflection 是最容易理解的一类反馈回路:生成一次结果,再由另一个角色给出反馈,然后继续改。
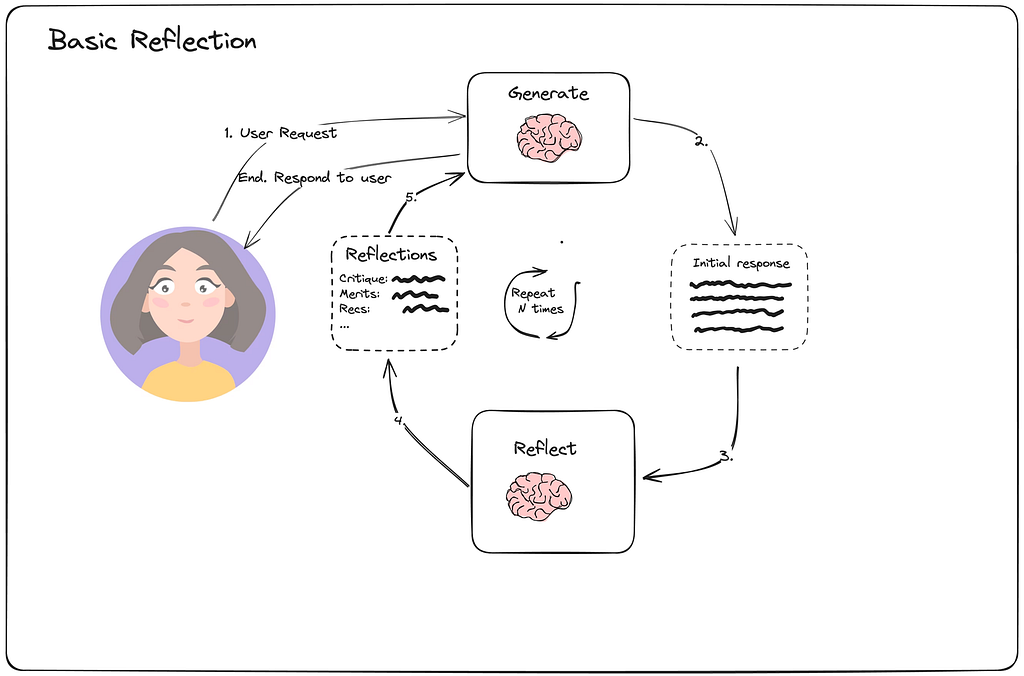
这个模式特别适合那些“一次写完通常不够好”的任务,比如:
- 长文生成
- 方案整理
- 代码草稿修订
它不一定需要复杂奖励机制,只要反馈目标明确,就能明显提升首稿质量。
4. Reflexion:把反馈从“点评”升级为“带外部依据的纠偏”
Reflexion 比 Basic Reflection 更进一步。它不是简单说一句“再改改”,而是要求模型结合外部结果去判断当前输出哪里冗余、哪里遗漏。
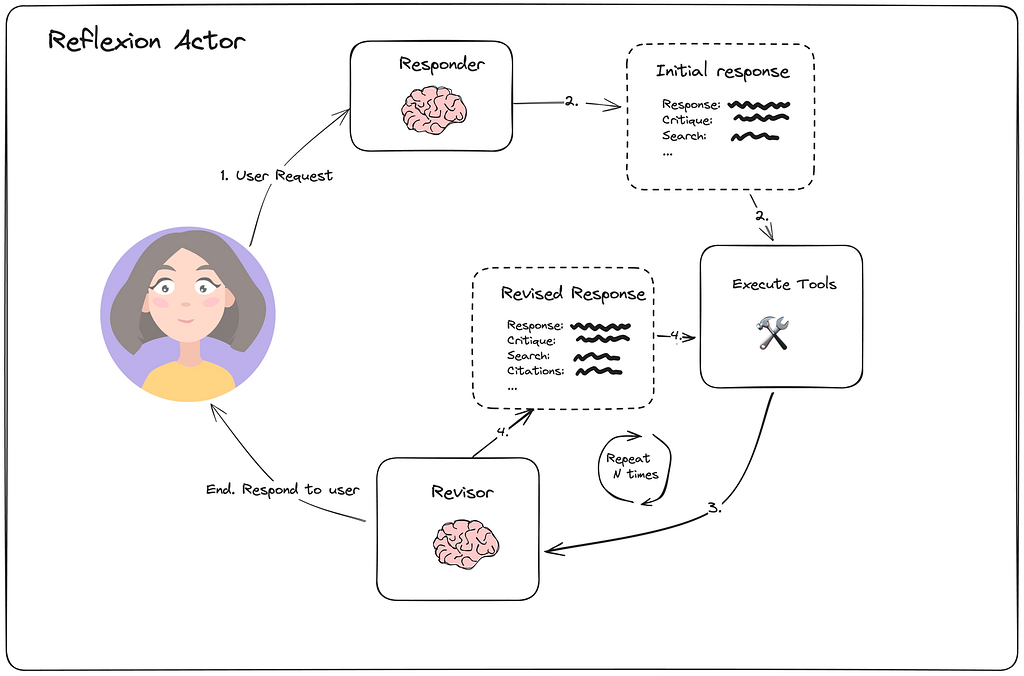
这类模式的价值在于:反馈不再只是语言风格层面的,而是开始触及正确性、覆盖度和缺失项。
如果任务的评价标准能被外部工具部分验证,Reflexion 往往比单纯自我反思更稳。
5. LATS:把搜索、规划、行动、反思塞进同一棵树
LATS 可以看成一个组合拳:把 Tree Search、ReAct、Plan & Solve、Reflection 这些东西合到一棵搜索树里。
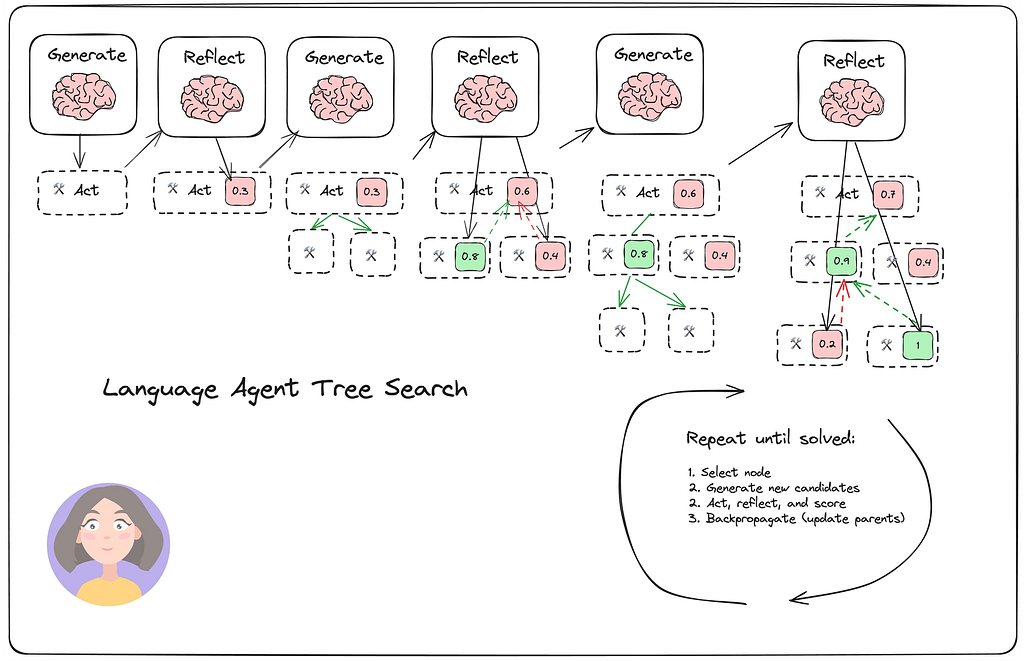
这个模式适合高难度任务,但也带来明显代价:
- 计算量大
- 状态管理复杂
- 调试成本高
所以 LATS 更像研究型或高价值任务的打法,而不是默认工程基线。多数业务场景根本不需要把搜索树开到这么深。
6. Self-Discovery:把反思粒度继续往下打
Self-Discovery 的重点不只是“结果对不对”,而是让模型重新思考:这个任务本身该怎么拆、每个组成部分该如何判断。
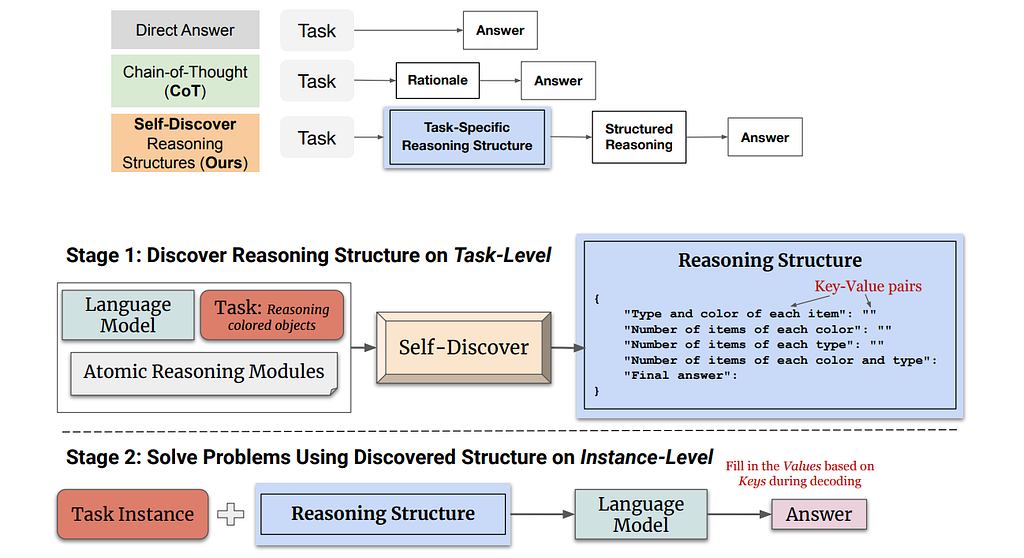
它更像是对任务理解层的一次回退和重构,而不是在既定步骤上做微调。
这类模式适合那些目标模糊、题型变化大、需要临时重建推理结构的任务。
7. Storm:先做大纲和检索,再回填成长文
Storm 针对的是长文生成这类任务。它的流程不是让模型从头直接写,而是先搜资料、先出提纲,再逐段展开。

这种结构尤其适合:
- 技术综述
- 研究笔记
- 类百科式内容生成
它的本质是把“写作”拆成“检索、组织、展开”三个阶段。对长文来说,这通常比单轮生成稳定得多。
五、把这些模式放回工程现场,应该怎么选
如果从工程视角收束一下,大致可以这样判断:
- 任务短、依赖环境反馈:优先 ReAct。
- 任务长、依赖明确、需要先分解:优先 Plan & Solve。
- 步骤可并行、多个子问题互不依赖:考虑 LLMCompiler。
- 首稿质量不够、需要复盘修订:加 Reflection / Reflexion。
- 需要探索多条候选路径:再考虑 LATS 这类更重的搜索型结构。
- 目标是长文整理与生成:Storm 这类“检索 + 大纲 + 展开”的多阶段流程更合适。
还有一个更重要的原则:不要为了模式而模式化。
很多 Agent 系统最后难用,不是因为缺了某个高级模式,而是因为把太多模式一股脑叠在一起,导致:
- 状态边界不清
- 工具输入输出不稳定
- 中间结果难观测
- 错误难回放
一个能上线的 Agent 工作流,往往不是最复杂的那个,而是最容易解释、最容易调试、最容易恢复的那个。
六、一个更实用的结论
这篇文章表面上在介绍模式,实际上指向的是同一个工程事实:
Agent 的核心不是模型人格,而是工作流结构。
模式本身没有银弹属性。ReAct、Plan & Solve、Reflection、LATS、Storm 这些名字背后,真正值得保留的是它们对系统问题的拆法:
- 什么时候该先想再做
- 什么时候该边做边看
- 什么时候该停下来复盘
- 什么时候该先并行收集再统一汇总
把这些问题想清楚,才有可能把 Agent 从“能跑 Demo”推进到“能稳定交付”。
来源:Medium / Binome
原文链接:https://medium.com/binome/ai-agent-workflow-design-patterns-an-overview-cf9e1f609696