
Agent 做不好真实任务,很多时候不是模型能力不够,而是上下文和工作方法没有被稳定交给它。
一个通用模型可以写代码、看文档、跑脚本,也能调用工具,但这不等于它天然知道团队的交付流程、产品约束、排障套路、数据口径和质量标准。把这些内容一遍遍塞进 prompt,短期能跑,规模一大就会失控:提示词越来越长,任务之间相互污染,老经验难复用,新经验也沉淀不下来。
Agent Skills 解决的正是这类问题。它的思路很简单:不要把经验散落在聊天里,而是把经验整理成一个目录,让 agent 在需要的时候自己去读、去执行、去引用。
一、Skill 不是一句提示词,而是一个目录
Skill 的最小单位不是一段说明,而是一个文件夹。核心文件叫 SKILL.md,其中至少要有两个元信息字段:name 和 description。除此之外,还可以带脚本、参考资料、模板、资源文件。
my-skill/
├── SKILL.md
├── scripts/
├── references/
├── assets/
└── ...
这种结构有几个直接好处:
- 经验可以版本化,和代码一样进入仓库管理
- 说明、脚本、样例、模板可以放在一起,不用分散在 Wiki、聊天记录和网盘
- 同一套 Skill 可以被不同 agent 或不同产品复用
和普通 prompt 相比,Skill 解决的是“可复用能力”的问题。和单纯的工具调用相比,Skill 解决的是“什么时候做、按什么流程做、遇到什么情况切换策略”的问题。
可以把它理解成给 agent 配的一份入职手册,只不过这份手册不是一次性整本塞进上下文,而是按需阅读。
二、核心机制是渐进式加载,不是一次性塞满上下文
Skill 最关键的设计,不是目录结构本身,而是 progressive disclosure,也就是分层按需加载。
一个可用的 Skill,通常会分成三层:
- 元数据层
- 指令层
- 资源与脚本层
1. 元数据层:先告诉模型“这是什么,什么时候用”
启动时,agent 只需要知道每个 Skill 的存在,以及它适用的任务类型。这个信息通常来自 SKILL.md 顶部的 YAML frontmatter。
---
name: pdf-processing
description: 提取 PDF 文本和表格、填写表单、合并文档。处理 PDF、表单或文档抽取任务时使用。
---
这一层信息很轻,成本也很低。模型不需要先把整个 Skill 吞进去,只要知道“有这样一个能力模块,命中这个场景时应该触发它”就够了。
2. 指令层:命中后再读完整流程
当任务和描述匹配时,agent 再去读取完整的 SKILL.md。这里放的是流程、约束、最佳实践、常见错误和操作顺序。
这一步解决的是“知道该做什么”。
3. 资源与脚本层:只在真正需要时再打开
如果 SKILL.md 里还引用了别的文件,例如:
FORMS.mdREFERENCE.mdschema.sqlscripts/fill_form.py
那么 agent 可以继续按需读取这些文件,或者直接运行脚本,而不是把所有内容一次性放进上下文。
这一步解决的是“做具体任务时,精确拿到当前需要的材料”。
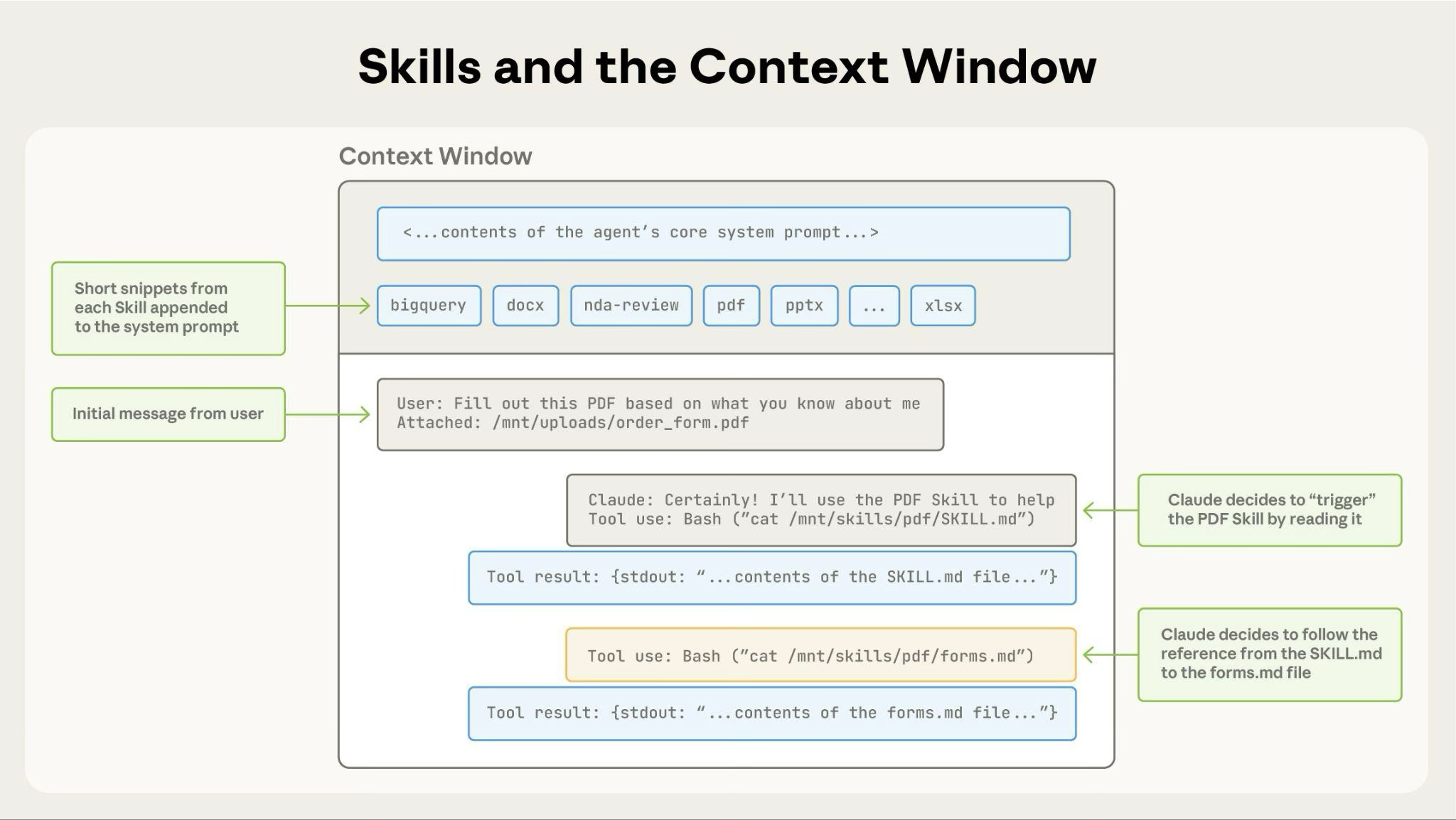
这套机制的价值非常直接:一个 Skill 可以带很多上下文,但上下文窗口里只保留当前任务真正需要的那一小部分。
三、为什么 Skill 比长 prompt 更稳
很多团队一开始会走到这样一条路上:
- 系统提示词里塞团队规范
- 用户提示词里塞任务说明
- 再附加一点 FAQ、示例、边界条件
早期看似能跑,后面通常会出现三个问题。
1. 重复劳动
相同的流程说明会在不同任务里重复出现,改一次要到处改。
2. 上下文污染
无关任务的指导和历史残留会一起进入窗口,模型容易把旧规则带到新任务里。
3. 扩展性差
当知识量继续增长时,prompt 既难维护,也难路由。模型会开始在一大堆相似规则里做模糊匹配。
Skill 的目录化方案,本质上是在把这些“长期有效的经验”从对话上下文里剥离出来,变成文件系统里的结构化资产。模型只在需要时加载它们,代价更低,也更容易维护。
四、文件系统是 Skill 能成立的前提
Skill 之所以不是“换一种写 prompt 的方式”,关键在于 agent 运行在一个可执行环境里。
在 Claude 的这套设计里,agent 拥有:
- 文件系统访问能力
- bash 执行能力
- 代码运行能力
这意味着 Skill 不是抽象概念,而是真实存在于目录里的文件集合。agent 触发 Skill 的动作,往往就是:
- 先看元数据判断是否相关
- 用 bash 读取
SKILL.md - 如有需要继续读取补充文件
- 如有需要直接运行脚本
- 只把输出结果带回上下文
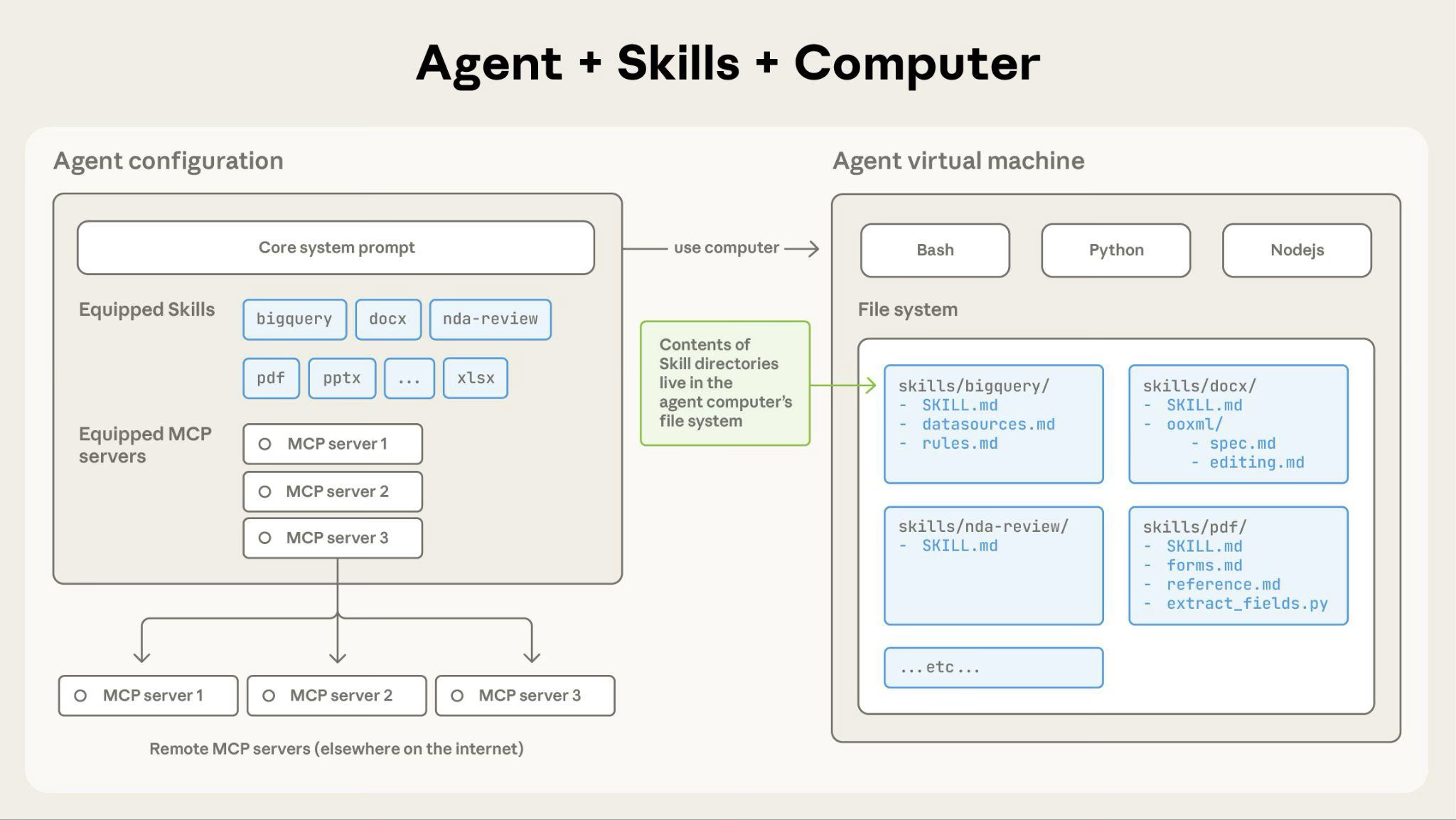
这里有个特别重要的点:脚本本身不需要进入上下文窗口,只要脚本执行结果进入上下文即可。
这带来两个收益:
- 确定性操作交给代码,成本更低,结果更稳定
- 大量参考资料和脚本可以常驻磁盘,而不是常驻 token
例如做 PDF 表单填写时,Skill 可以让 agent 直接运行一个现成的 Python 脚本,提取表单字段,再按规则填写。比起让模型临时现写一遍解析逻辑,这种方式更可靠,也更节省上下文。
五、一个好的 Skill,应该把“路由条件”写清楚
Skill 的 description 不只是介绍语,它本质上是路由规则。
如果描述写得太宽泛,agent 会误触发;写得太窄,又会错过适用场景。比较稳的写法通常要同时包含两部分:
- 这个 Skill 做什么
- 在什么情况下使用它
例如:
- “处理 PDF 文本提取、表格抽取、表单填写”
- “当用户提到 PDF、表单、合同、扫描件处理时使用”
比起“PDF 工具”这种过短描述,第二种写法更容易让模型正确命中。
这一点和写 tool description 很像,但 Skill 的描述更偏“工作流级能力”,不是单次函数调用。
六、Skill 的边界,不是替代工具,而是组织工具的使用方式
Skill、tool、MCP 经常会被混在一起说,但它们解决的不是同一层问题。
可以简单分成三层:
| 层级 | 解决的问题 | 典型形态 |
|---|---|---|
| Prompt | 当前这轮要怎么回答 | 一段临时指令 |
| Tool / MCP | 能做什么动作 | API、命令、外部系统连接 |
| Skill | 在某类任务里,应该按什么流程组合上下文、规则和工具 | 目录 + SKILL.md + 资源/脚本 |
Skill 并不替代工具。相反,它通常是组织工具使用方式的那一层。
例如:
- MCP 提供数据库访问能力
- bash 提供文件读取与脚本执行能力
- 浏览器工具提供页面操作能力
- Skill 负责告诉 agent:什么时候该查数据库、什么时候该读哪份文档、什么时候要跑哪个脚本、结果如何验证
所以 Skill 和 MCP 更像互补关系:MCP 负责接外部系统,Skill 负责把复杂流程教给 agent。
七、Skill 要为规模化准备,而不是只为一次成功准备
如果 Skill 只是给某个单点任务写一大段说明,很快就会重新退化成“大 prompt”。
更可维护的做法通常有三个。
1. 把互斥场景拆开
如果某些上下文只在特定子任务下才需要,就不要塞进同一份核心说明里。拆成单独文件,让 agent 按需进入。
2. 把确定性操作交给脚本
排序、校验、格式转换、表单提取、结构比对,这些都更适合放进脚本,而不是反复让模型生成。
3. 从评测和失败样本出发
不要先拍脑袋写一个很大的 Skill,再期待模型自己学会。更稳的做法是:
- 先拿真实任务跑
- 观察 agent 卡在哪里
- 补足缺失上下文或脚本
- 继续迭代
Skill 本质上是把“这类任务为什么会失败”反向沉淀成可复用能力。
八、从 agent 的视角写 Skill,而不是从作者自己的视角写
写 Skill 时最容易犯的错误,是作者默认很多背景知识已经被理解了。
但 agent 只能看到当前上下文和文件系统里的内容,它并不会自动继承作者的脑内前提。写得好的 Skill,通常会具备这几个特征:
- 触发条件明确
- 步骤顺序清楚
- 哪些文件要读、哪些脚本要跑,指向明确
- 成功标准和失败处理写得具体
- 例外情况能被识别
可以把这个过程理解成给一个新同事交接工作。不是解释“理念上应该怎么做”,而是让他第一次上手就能按流程跑通。
九、安全问题不能忽略,Skill 本质上就是“带说明的可执行包”
Skill 强大的原因,恰恰也是它风险较高的原因。
因为一个 Skill 里既有说明,也可能有脚本、资源文件、网络访问和工具调用。如果来源不可信,它完全可能诱导 agent 去做不该做的事情。
需要重点注意的风险包括:
- 恶意脚本或异常依赖
- 不必要的网络访问
- 对本地文件或敏感数据的越权读取
- 利用说明文本诱导 agent 滥用工具
把 Skill 当成“普通提示词模板”看待是不够的,更合理的心态是把它当成一种轻量软件包。
更稳的使用方式是:
- 只安装可信来源的 Skill
- 审核
SKILL.md、脚本和资源文件 - 特别关注外部 URL、网络访问和文件操作
- 在生产环境里配合最小权限原则
十、Agent Skills 真正有价值的地方,是把经验变成可移植资产
agentskills.io 把 Skill 格式进一步开放化,意义并不只是“多一个规范”,而是把原本容易绑定在单一产品里的经验,抽象成一个可移植的能力单元。
只要客户端支持这个格式,同一套 Skill 理论上就能在不同 agent 产品里复用。这样沉淀下来的就不是“某个模型的一次对话结果”,而是团队自己的方法库。
这件事对组织尤其重要,因为很多高价值知识并不在公开文档里,而是存在于:
- 团队流程
- 业务规则
- 排障顺序
- 质量标准
- 历史经验
把这些经验做成 Skill,等于把原本依附在人身上的隐性知识,逐步转成 agent 可调用的工作资产。
结语
Agent Skills 解决的不是“模型会不会做”,而是“模型在实际工程环境里,怎样稳定地拿到正确上下文、执行正确流程,并把经验沉淀成可复用能力”。
如果一个团队已经开始认真使用 agent,Skill 迟早会变成基础设施层的一部分。因为只靠 prompt,不可能长期承载复杂流程;只靠工具,也不足以表达任务方法。真正能让 agent 逐步变得可用、可复用、可迁移的,是把知识、流程、脚本和资源组织成一套按需加载的能力模块。
下一步真正值得投入的,不是继续堆更长的指令,而是开始整理第一批值得沉淀成 Skill 的工作流。
参考来源:
https://agentskills.io/home
https://platform.claude.com/docs/en/agents-and-tools/agent-skills/overview
https://claude.com/blog/equipping-agents-for-the-real-world-with-agent-skills